DoShiCo is a benchmark to compare the performance of different deep neural network policies on the task of monocular collision avoidance. Between the simulated and the real world is a very large domain shift. Dealing with this domain shift is crucial for making deep neural policies perform well in the real world. It is however very difficult to compare different training methods or architectures as long as there is no clear benchmark. DoShiCo responds to this demand.
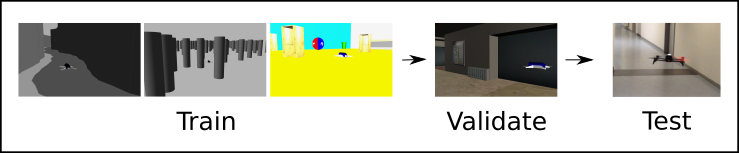
DoShiCo represents a dummy domain shift in simulation as well as an offline test bench with real-world data. The training happens in three types of basic simulated environments defined in Gazebo.
- Canyon: a corridor of two straight walls with constant width and bending corners varying in angle. Flying distance: 45m
- Forest: a set of cylinders on varying locations with constant density. Flying distance: 45m
- Sandbox: a big room in varying colors and objects randomly selected from 13 different models. Flying distance: 7m
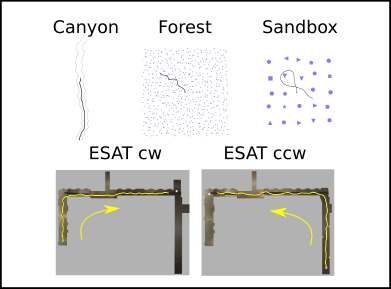
Validation happens by flying online through a more realistic environment, called ESAT.
In order to get a sense of the performance in the real world, an offline almost-collision dataset is provided in which collision would certainly occur if the wrong action was applied. Flying online in the real world can be tedious and is very dependent on external factors like wifi connections or battery status. The almost-collision dataset makes it possible to compare policies on real-world data quantitatively.

More details can be found in our paper.
Training deep neural control networks end-to-end for real-world applications typically requires big demonstration datasets in the real world or big sets consisting of a large variety of realistic and closely related 3D CAD models. These real or virtual data should, moreover, have very similar characteristics to the conditions expected at test time. These stringent requirements and the time consuming data collection processes that they entail, are probably the most important impediment that keeps deep neural policies from being deployed in real-world applications. Therefore, we advocate an alternative approach, where instead of avoiding any domain shift by carefully selecting the training data, the goal is to learn a policy that can cope with this domain shift. To this end, we propose a new challenge: to train a model in very basic synthetic environments, far from realistic, in a way that it can fly in more realistic environments as well as take the control decisions on real-world data.
The code and rules for benchmarking are explained here.